 Grow and let grow!
Grow and let grow!
|
|
SHODHAKA Life Sciences Pvt. Ltd. |
|
|
||
The available literature search tools specialize in different aspects and hence their features vary drastically. When attempting to gather citations for an objective, one can obtain entirely different results from different tools. This variation in the results is mainly because of the differences in four aspects of search:
Practical comparisons of the citation retrieval efficiencies are straight forward when using a fixed set of query terms applied uniformly across all search engines. It will also be important to assess the practical use of the tools in context of specific objectives by considering the query design features offeredby the search tools. To balance both the approaches, both types of searches, fixed-query-set and objective-oriented (varying query sets) searches, were performed.
It is very difficult to determine the actual number of relevant hits within any one set of results and almost impossible to determine the total number of relevant citations contained in a database. Hence, we tried to determine an ‘Indicative Precision Score’ and a ‘Relative Recall Score’ (defined in the main text).
- flexibility in determining the set of query terms/phrases,
- methods employed to scan the query sets in the documents,
- extent to which a document is scanned (only citation [title, abstract and the details of authors and the journal] or the complete document) and
- the number as well as the type of documents scanned.
Practical comparisons of the citation retrieval efficiencies are straight forward when using a fixed set of query terms applied uniformly across all search engines. It will also be important to assess the practical use of the tools in context of specific objectives by considering the query design features offeredby the search tools. To balance both the approaches, both types of searches, fixed-query-set and objective-oriented (varying query sets) searches, were performed.
It is very difficult to determine the actual number of relevant hits within any one set of results and almost impossible to determine the total number of relevant citations contained in a database. Hence, we tried to determine an ‘Indicative Precision Score’ and a ‘Relative Recall Score’ (defined in the main text).
The method used to calculate the ‘Indicative Precision Score’ and ‘Relative Recall Score’ is described below:
Initial study (round I) involved 18 tools, of which few were selected for the detailed analysis. Less efficient tools were filtered out based on their precision and recall abilities in round I. In the second round, query sets were designed by making the best use of query features in each of the selected tools with the subsequent refining of the formulas for sampling and score calculations. Following method was employed to sample the hits obtained and to analyze the precision and recall of the tools.
i.Sample size determination:
The method employed, in first round, of relevance determination is illustrated below with an example:
Total hits for a query (query: “liver and toxicity”) in Scopus: 1007
Selected sample size: 140
The method employed, in second round, of relevance determination is illustrated below:
Wherever possible, all hits were analyzed. In certain cases, sampling was done using the general formula:
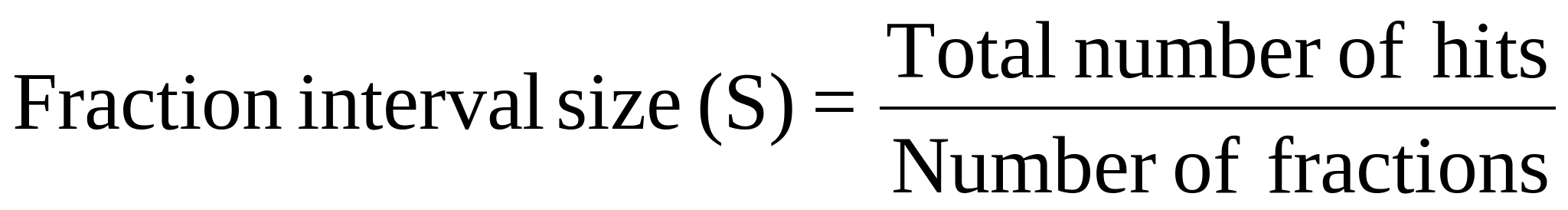
Formula used for determining sample size per fraction: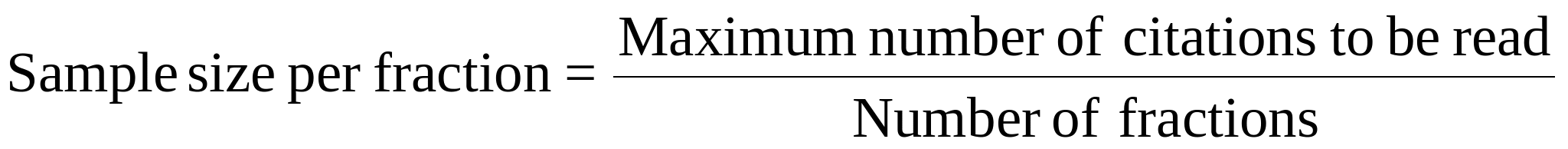
Note:
iii.Indicative Exclusive Contribution Score (IECS)
iv.Calculation of the Relative Recall Score (RRS):
Hence the total number of relevant hits among the results (TRH) = trh-I + trh-II
Total hits for a query (query: “liver and toxicity”) in Scopus: 1007
Selected sample size: 140
|
Sample subset possible (no. of abstracts) |
Number of relevant hits (rh) |
Number of most probably relevant hits (mprh) |
(RH=rh+mprh) |
|
First 20 (20) |
18 |
2 |
20 (RH1) |
|
100-120(20) |
14 |
2 |
16 (RH2) |
|
200-220 (20) |
12 |
4 |
16 (RH3) |
|
500-540 (40) |
25 |
6 |
31 (RH4, 5) |
|
…. |
…. |
…. |
…. |
|
960-1000 (40) |
25 |
9 |
34 (RH6, 7) |
|
TOTAL = 140 |
94 |
23 |
117 (RH) |
The method employed, in second round, of relevance determination is illustrated below:
Wherever possible, all hits were analyzed. In certain cases, sampling was done using the general formula:
Formula used for determining sample size per fraction:
Note:
Sampling was done only when the total number of hits exceeded a manageable count (approximately 350). In other cases, all the citations were analyzed
dNumber of fractions was always ten.
The sample size (i.e., the maximum number of citations to be read) varied depending on the total number of hits but not directly proportional to it
ii.Calculation of Indicative Precision Score (IPS) - 200: If the total No. of hits obtained is less than 2000.i
- 250: If the total No. of hits obtained are in between 2001 – 4000.
- 350: If the total No. of hits obtained is greater than 4000.
First a Preliminary Precision Score (PPS) was calculated:
PPS = ((RH/total hits scanned)*100*2) + ((MRH/ total hits scanned)*100)
Where,
RH: relevant + most probably relevant
MRH: may be relevant + most probably irrelevant
Example: PPS = ((117/140)*100*2) + ((23/140)*100) = 183.5
Note:
The percentage RH has been multiplied by 2 to increase its contribution to the total score.
Since the number of hits analyzed for each query in each tool was different, the calculated scores (PPSs) were not apt to compare the precision across the tools. Therefore, an “Equivalence score” was calculated for each tool, wherein, the calculated scores across the tools, for each search, were distributed into ten equal classes, between the highest and the lowest scores. A score was then assigned, based on the class of previously calculated score, with the highest being scored as 10 and least as 1.
Ranking was done on a 1 to 10 scale with each division representing 1/10th of the difference between the highest PPS and the lowest.
For example, in PPS for query set 1,
The maximum PPS is 48 (Google Scholar & HighWire Press) and minimum is 18 (for Scirus), hence 1/10th of the difference between the highest PPS and the lowestwill be 3, as shown below:
46 to 48 = eq. score 10
43 to 45 = eq. score 9
40 to 42 = eq. score 8
.
.
21 to 23 = eq. score 2
18 to 20 = eq. score 1
The final ‘Indicative Precision Score’ was calculated for each tool by taking a mean of such equivalence score or ranking for the three different searches (see Supplementary notes 7, Tables 1 & 3).
PPS = ((RH/total hits scanned)*100*2) + ((MRH/ total hits scanned)*100)
Where,
RH: relevant + most probably relevant
MRH: may be relevant + most probably irrelevant
Example: PPS = ((117/140)*100*2) + ((23/140)*100) = 183.5
Note:
The percentage RH has been multiplied by 2 to increase its contribution to the total score.
Since the number of hits analyzed for each query in each tool was different, the calculated scores (PPSs) were not apt to compare the precision across the tools. Therefore, an “Equivalence score” was calculated for each tool, wherein, the calculated scores across the tools, for each search, were distributed into ten equal classes, between the highest and the lowest scores. A score was then assigned, based on the class of previously calculated score, with the highest being scored as 10 and least as 1.
Ranking was done on a 1 to 10 scale with each division representing 1/10th of the difference between the highest PPS and the lowest.
For example, in PPS for query set 1,
The maximum PPS is 48 (Google Scholar & HighWire Press) and minimum is 18 (for Scirus), hence 1/10th of the difference between the highest PPS and the lowestwill be 3, as shown below:
46 to 48 = eq. score 10
43 to 45 = eq. score 9
40 to 42 = eq. score 8
.
.
21 to 23 = eq. score 2
18 to 20 = eq. score 1
The final ‘Indicative Precision Score’ was calculated for each tool by taking a mean of such equivalence score or ranking for the three different searches (see Supplementary notes 7, Tables 1 & 3).
iii.Indicative Exclusive Contribution Score (IECS)
PECS = ((Erh/total hits scanned)*100*2) + (Emrh/total hits scanned)*100)
Where,
PECS = Preliminary Exclusive Contribution Score
Erh = Exclusive relevant hits
Emrh = Exclusive may be relevant hits
An equivalence score for every PECS was calculated, as with the precision score calculations, for each tool. The mean of such equivalence scores for different searches provided the final ‘IECS’ (see Supplementary notes 7, Table 5). Go to Top
Where,
PECS = Preliminary Exclusive Contribution Score
Erh = Exclusive relevant hits
Emrh = Exclusive may be relevant hits
An equivalence score for every PECS was calculated, as with the precision score calculations, for each tool. The mean of such equivalence scores for different searches provided the final ‘IECS’ (see Supplementary notes 7, Table 5). Go to Top
iv.Calculation of the Relative Recall Score (RRS):
Total Relevant Hits (trh) were calculated among the first 540 citations (trh-I) by using the formula:
trh-I = (540/20) x M20
where,
M20 = (RH1+RH2+RH3+RH4,5)/5
In this case, M20 = (20+16+16+31)/5 = 16.6
trh-I = 448.2
Similarly the total relevant hits among the rest of the hits (trh-II) were calculated using the formula:
trh-II = [(total hits - 540) / (40)] x [(RH6,7)]
In the current example, trh-II = [467/40] x [34] =396.95
where,
M20 = (RH1+RH2+RH3+RH4,5)/5
In this case, M20 = (20+16+16+31)/5 = 16.6
trh-I = 448.2
Similarly the total relevant hits among the rest of the hits (trh-II) were calculated using the formula:
trh-II = [(total hits - 540) / (40)] x [(RH6,7)]
In the current example, trh-II = [467/40] x [34] =396.95
Hence the total number of relevant hits among the results (TRH) = trh-I + trh-II
In this case, TRH of Scopus is, 448.2+396.95, i.e., 845.15
The TRH calculations in round 2 differed slightly, since the fraction size was always kept at a constant of 20 articles. In most of the cases, there was no sampling done and hence the number of relevant hits directly represented the TRH.
To compare the TRH across the tools, a ratio of each tool’s TRH to the maximum possible relevant hits retrieved by any tool was first determined. In all the three searches that we performed, Google Scholar showed the maximum number of hits (though it displays only up to 1000). Therefore, the maximum possible relevant hits that Google Scholar could have retrieved if it displayed all the hits (RHmax), was taken as the highest reference point for calculating the relative recall. A Preliminary Relative Recall Score (PRRS) was then calculated individually for each tool per query using the formula,
PRRS = (TRH*100)/ Rhmax.
As with the precision score calculations, an equivalence score for PRRS was calculated for each tool. The mean of such equivalence scores for the three different searches provided the final ‘Relative Recall Score’ (see Supplementary notes 7, Tables 2 & 4). The significant difference between the means was also calculated using two-tailed t-test analysis.
The TRH calculations in round 2 differed slightly, since the fraction size was always kept at a constant of 20 articles. In most of the cases, there was no sampling done and hence the number of relevant hits directly represented the TRH.
To compare the TRH across the tools, a ratio of each tool’s TRH to the maximum possible relevant hits retrieved by any tool was first determined. In all the three searches that we performed, Google Scholar showed the maximum number of hits (though it displays only up to 1000). Therefore, the maximum possible relevant hits that Google Scholar could have retrieved if it displayed all the hits (RHmax), was taken as the highest reference point for calculating the relative recall. A Preliminary Relative Recall Score (PRRS) was then calculated individually for each tool per query using the formula,
PRRS = (TRH*100)/ Rhmax.
As with the precision score calculations, an equivalence score for PRRS was calculated for each tool. The mean of such equivalence scores for the three different searches provided the final ‘Relative Recall Score’ (see Supplementary notes 7, Tables 2 & 4). The significant difference between the means was also calculated using two-tailed t-test analysis.
copyright © shodhaka life sciences private limited; all rights reserved